Drilling Log Imputation
Project Goals
Data scientists who trained Machine Learning models for drilling log imputations using Spark Beyond and wanting to host the models outside the vendor platform. Models required horizontal scaling and a light orchestrator was built.
Summary of Results
- Processed 7 Million predictions in 2-hrs vs ~3-hrs using VMs.
- Scales from 0 to ready in < 10 mins
- Flexible resource on per model basis
- Options to also use spot and gpu instances
- Able to use model exported in Docker Image from discovery platform
- Requires user to have their notebook running for later processing
Project Team
Ståle Langeland (Data Scientist)
Matt Li (MLOps Architect)
MLOps Challenges
Model Hosting Environment Different from Model Training
The Machine Learning model was trained in Spark Beyond's Discovery platform which provided some useful features for the Data Scientists. However, the Discovery platform did not have capabilities to deploy the models. Therefore, model exported by the Discovery Platform in Docker Image needed to be hosted on outside the platform. It was decided to host the entire model serving architecture on Aurora AKS cluster to leverage scale and the power of kubernetes.
Need to Implement Queue Store Predictions Requests
Multiple users needed to make large number of prediction requests to the model endpoint. In order to keep track of requests, implementation of queue was needed from which workers can consume and process the requests. The results of these requests will then be sent back to their respective users.
Need for Multiple Workers to Process Requests
Due to an extremely large volume of prediction requests, it required multiple workers to process them. Scale and power of kubernetes makes convenient to deploy multiple workers as per need of the models and desired processing time.
MLOps Solutions
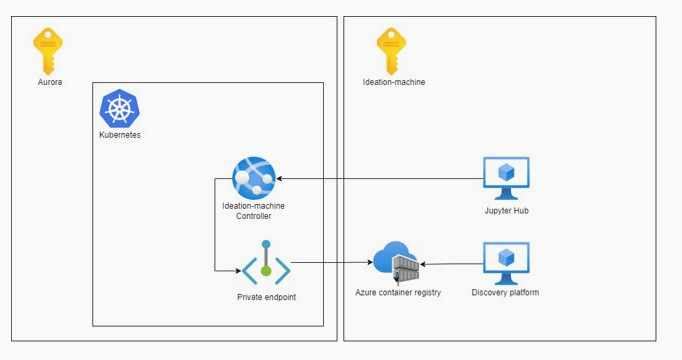
Model Serving
The model was served using FastAPI Server framework in Python which was packaged inside the docker container. This was then deployed using Kubernetes Deployment manifest with predefined set of replicas and resources per replica. This deployment was deployed using helmchart.
Prediction Queue - Redis
Prediction queue was implemented using Redis Data Access Object (DAO)
https://github.com/equinor/ideation-machine-controller/blob/master/controller/redis_client.py
GitHub Repos
Ideation Machine Model Python Code:
https://github.com/equinor/ideation-machine-controller/tree/master
Ideation Machine Infrastructure:
https://github.com/equinor/ideation-machine-infrastructure