CV MLOps Architecture
Development architecture
The development stage architecture is set up to:
- Start in a dev notebook container → run experiments using Jupyter + CV tools
- Tune models with Ray Tune → log results to MLflow
- Deploy and serve model → deploy with KServe for real-time REST inference
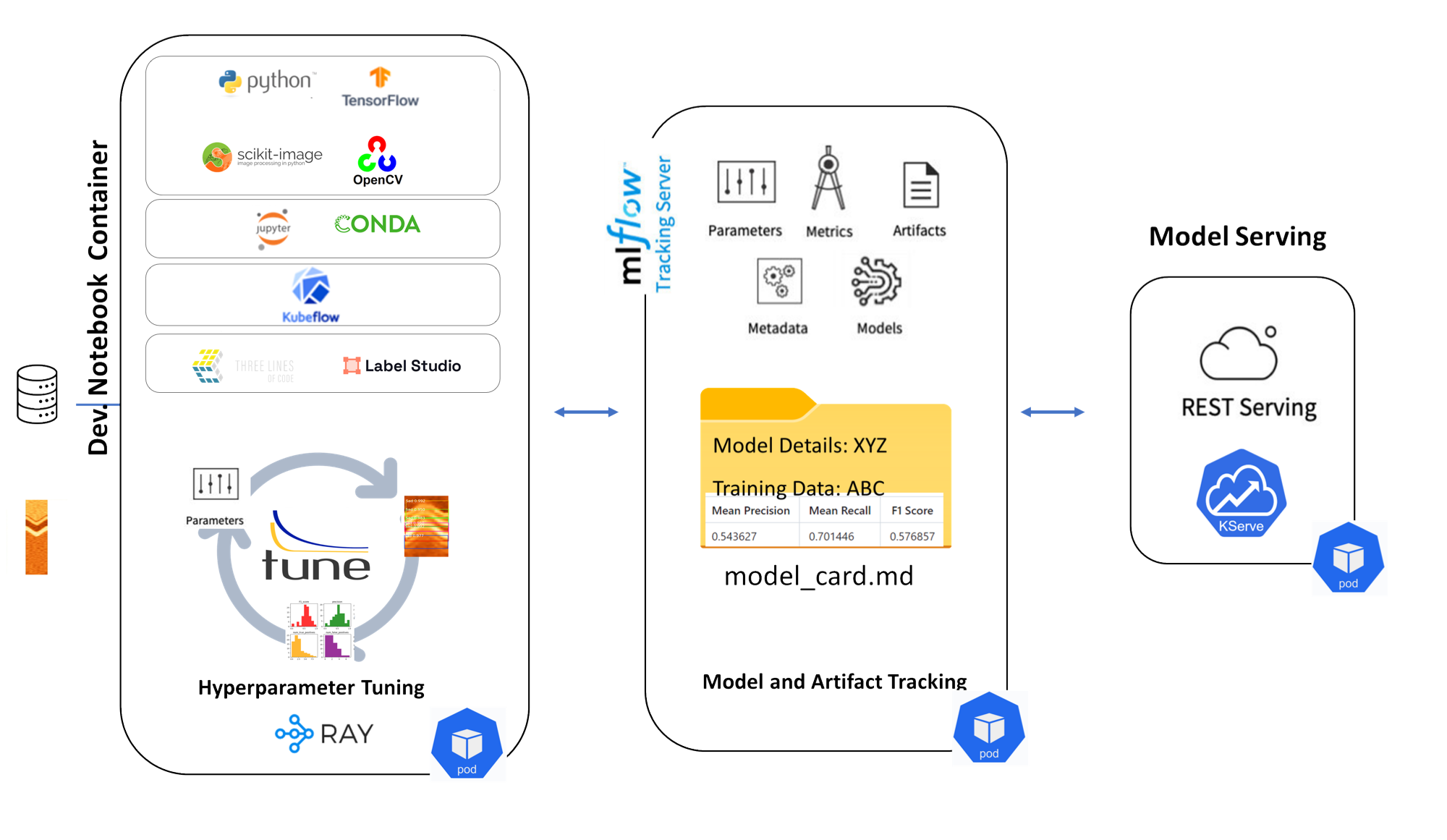 Figure 1: Development stage architecture diagram
Figure 1: Development stage architecture diagram
Toggle for description of the architecture diagram (Figure 1).
Dev Notebook Container
MLflow Tracking Server
Model Serving
Foundational libraries
- Python, TensorFlow, OpenCV, scikit-image: core CV and ML libraries
Interactive development
- Jupyter, Conda: for developing, running, and managing environments in notebooks
Orchestration & resource management
- Kubeflow: manages pipelines, execution, and resource orchestration
Model training & data quality
- Three Lines of Code (3LC): simplifies model training
- Label Studio: labeling and data versioning
Hyperparameter Tuning
- Uses Ray Tune, a scalable hyperparameter tuning library
- Automatically varies parameters and retrains models to find optimal settings
Logs and tracks
- Parameters (e.g., learning rate, batch size)
- Metrics (e.g., accuracy, F1 score)
- Artifacts (e.g., trained model files, plots)
- Model metadata and versions
Model Card
- Summarizes model details, training dataset, and evaluation metrics (like Mean Precision, Recall, F1 Score)
- Helps maintain model documentation and reproducibility
KServe
- A standard model inference platform on Kubernetes, built for scalable, production-grade ML serving
- Supports real-time inference via a REST API with a standardized protocol across ML frameworks
- Enables modern serverless inference workloads with autoscaling (e.g., Scale to Zero, GPU-based)
- Provides advanced deployment strategies such as canary rollouts, ensembles, and model transformers
- Supports pre/post-processing, monitoring, and explainability
- Integrates with ModelMesh for intelligent routing and high-density model serving
Deployment architecture
Data and metric flow are set up as follows:
- Input data flows in from the K8s Persistent Volume
- Data travels through each pipeline stage
- Results and logs are captured by MLflow
- Deployment can then trigger serving or monitoring
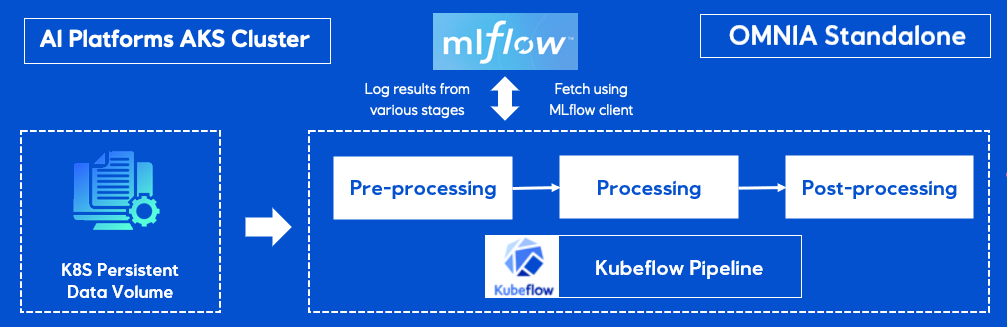 Figure 2: Deployment stage architecture diagram
Figure 2: Deployment stage architecture diagram
Toggle for description of the architecture diagram (Figure 2).
AI Platform AKS Cluster
Kubeflow Pipeline
MLflow Integration
- The architecture is deployed on an AI Platform Azure Kubernetes Service (AKS) cluster.
- Kubernetes (K8S) Persistent Data Volume stores data used in Kubeflow pipeline stages.
Core workflow composed of three main stages:
- Pre-processing
- Processing
- Post-processing
- MLflow logs results from each of the Kubeflow pipeline stages.
- MLflow client used to request logged run data